Martin Odersky、Lex Spoon 和 Julien Richard-Foy
這篇文章說明如何實作自訂集合類型,並建立在集合架構上。建議先閱讀有關 集合架構 的文章。
如果您想整合一個新的集合類別,以便它能從所有預定義的運算中獲益,使用正確的類型,您需要做什麼?在接下來的幾個部分中,您將會看到三個執行此操作的範例,分別是封頂序列、RNA 鹼基序列和使用 Patricia tries 實作的前置字元對應。
封頂序列
假設您想要建立一個不可變集合,其中包含最多 n 個元素:如果新增更多元素,則會移除第一個元素。
第一個任務是找出我們集合的超類型:它是 Seq、Set、Map 還是 Iterable?在我們的案例中,很容易選擇 Seq,因為我們的集合可以包含重複的項目,而且迭代順序由插入順序決定。然而,Seq 的一些屬性 並不符合
(xs ++ ys).size == xs.size + ys.size
因此,作為基本集合類型的唯一明智選擇是 collection.immutable.Iterable。
第一個版本的 Capped 類別
import scala.collection._
class Capped1[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A] { self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped1[B] = {
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if (length == capacity) {
newElems(offset) = elem
((offset + 1) % capacity, length)
} else {
newElems(length) = elem
(offset, length + 1)
}
new Capped1[B](capacity, newLength, newOffset, newElems)
}
@`inline` def :+ [B >: A](elem: B): Capped1[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = new AbstractIterator[A] {
private var current = 0
def hasNext = current < self.length
def next(): A = {
val elem = self(current)
current += 1
elem
}
}
override def className = "Capped1"
}
import scala.collection.*
class Capped1[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A]:
self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped1[B] =
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if length == capacity then
newElems(offset) = elem
((offset + 1) % capacity, length)
else
newElems(length) = elem
(offset, length + 1)
Capped1[B](capacity, newLength, newOffset, newElems)
end appended
inline def :+ [B >: A](elem: B): Capped1[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = new AbstractIterator[A]:
private var current = 0
def hasNext = current < self.length
def next(): A =
val elem = self(current)
current += 1
elem
end iterator
override def className = "Capped1"
end Capped1
上述清單顯示了我們封頂集合實作的第一個版本。它將在稍後進行精煉。類別 Capped1 有私有建構函式,它將集合容量、長度、偏移量(第一個元素索引)和基礎陣列作為參數。公開建構函式只會取得集合的容量。它將長度和偏移量設定為 0,並使用一個空的元素陣列。
appended 方法定義元素如何附加到指定的 Capped1 集合:它會建立一個新的底層元素陣列,複製目前的元素,並加入新的元素。只要元素數量沒有超過 capacity,新元素就會附加在之前的元素之後。然而,一旦達到最大容量,新元素就會取代集合中的第一個元素(在 offset 索引)。
apply 方法實作索引存取:它會透過加入 offset,將指定的索引轉換為底層陣列中對應的索引。
這兩個方法,appended 和 apply,實作 Capped1 集合類型的特定行為。除了它們之外,我們必須實作 iterator,才能讓一般集合操作(例如 foldLeft、count 等)在 Capped1 集合上運作。我們在此使用索引存取來實作它。
最後,我們覆寫 className 以傳回集合的名稱,“Capped1”。這個名稱會由 toString 操作使用。
以下是與 Capped1 集合的一些互動
scala> val c0 = new Capped1(capacity = 4)
val c0: Capped1[Nothing] = Capped1()
scala> val c1 = c0 :+ 1 :+ 2 :+ 3
val c1: Capped1[Int] = Capped1(1, 2, 3)
scala> c1.length
val res2: Int = 3
scala> c1.lastOption
val res3: Option[Int] = Some(3)
scala> val c2 = c1 :+ 4 :+ 5 :+ 6
val c2: Capped1[Int] = Capped1(3, 4, 5, 6)
scala> val c3 = c2.take(3)
val c3: collection.immutable.Iterable[Int] = List(3, 4, 5)
您可以看到,如果我們嘗試使用超過四個元素來擴充集合,則會捨棄第一個元素(請參閱 res4)。除了最後一個操作以外,其他操作的行為符合預期:在呼叫 take 之後,我們會取得 List,而不是預期的 Capped1 集合。這是因為在 類別 Capped1 中所做的所有事情,就是讓 Capped1 擴充 immutable.Iterable。這個類別有一個 take 方法,會傳回 immutable.Iterable,而這是根據 immutable.Iterable 的預設實作 List 來實作的。因此,這就是您在先前互動的最後一行中所看到的內容。
現在您了解為什麼事情會變成這樣,接下來的問題應該是需要做些什麼來改變它們?執行此操作的方法之一是在類別 Capped1 中覆寫 take 方法,也許像這樣
def take(count: Int): Capped1 = …
這會為 take 執行工作。但是 drop、filter 或 init 呢?事實上,集合中有超過五十個方法會再傳回一個集合。為了保持一致性,所有這些都必須被覆寫。這看起來越來越不像一個有吸引力的選項。幸運的是,有一個更簡單的方法可以達到相同的效果,如下一節所示。
第二版的 Capped 類別
import scala.collection._
class Capped2[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A]
with IterableOps[A, Capped2, Capped2[A]] { self =>
def this(capacity: Int) = // as before
def appended[B >: A](elem: B): Capped2[B] = // as before
@`inline` def :+ [B >: A](elem: B): Capped2[B] = // as before
def apply(i: Int): A = // as before
def iterator: Iterator[A] = // as before
override def className = "Capped2"
override val iterableFactory: IterableFactory[Capped2] = new Capped2Factory(capacity)
override protected def fromSpecific(coll: IterableOnce[A]): Capped2[A] = iterableFactory.from(coll)
override protected def newSpecificBuilder: mutable.Builder[A, Capped2[A]] = iterableFactory.newBuilder
override def empty: Capped2[A] = iterableFactory.empty
}
class Capped2Factory(capacity: Int) extends IterableFactory[Capped2] {
def from[A](source: IterableOnce[A]): Capped2[A] =
(newBuilder[A] ++= source).result()
def empty[A]: Capped2[A] = new Capped2[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped2[A]] =
new mutable.ImmutableBuilder[A, Capped2[A]](empty) {
def addOne(elem: A): this.type = { elems = elems :+ elem; this }
}
}
class Capped2[A] private(val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A],
IterableOps[A, Capped2, Capped2[A]]:
self =>
def this(capacity: Int) = // as before
def appended[B >: A](elem: B): Capped2[B] = // as before
inline def :+[B >: A](elem: B): Capped2[B] = // as before
def apply(i: Int): A = // as before
def iterator: Iterator[A] = // as before
override def className = "Capped2"
override val iterableFactory: IterableFactory[Capped2] = Capped2Factory(capacity)
override protected def fromSpecific(coll: IterableOnce[A]): Capped2[A] = iterableFactory.from(coll)
override protected def newSpecificBuilder: mutable.Builder[A, Capped2[A]] = iterableFactory.newBuilder
override def empty: Capped2[A] = iterableFactory.empty
end Capped2
class Capped2Factory(capacity: Int) extends IterableFactory[Capped2]:
def from[A](source: IterableOnce[A]): Capped2[A] =
(newBuilder[A] ++= source).result()
def empty[A]: Capped2[A] = Capped2[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped2[A]] =
new mutable.ImmutableBuilder[A, Capped2[A]](empty):
def addOne(elem: A): this.type =
elems = elems :+ elem; this
end Capped2Factory
Capped 類別不僅需要繼承自 Iterable,也需要繼承自其實作特質 IterableOps。這在上述 Capped2 類別清單中顯示。新的實作僅在兩個方面與前一個實作不同。首先,Capped2 類別現在也延伸 IterableOps[A, Capped2, Capped2[A]]。其次,其 iterableFactory 成員被覆寫為傳回 IterableFactory[Capped2]。如前一節所述,IterableOps 特質以通用方式實作 Iterable 的所有具體方法。例如,take、drop、filter 或 init 等方法的傳回類型是傳遞給 IterableOps 類別的第三個類型參數,即在 Capped2 類別中,它是 Capped2[A]。類似地,map、flatMap 或 concat 等方法的傳回類型是由傳遞給 IterableOps 類別的第二個類型參數定義的,即在 Capped2 類別中,它本身就是 Capped2。
傳回 Capped2[A] 集合的運算在 IterableOps 中實作,其根據 fromSpecific 和 newSpecificBuilder 運算實作。 immutable.Iterable[A] 父類別實作 fromSpecific 和 newSpecificBuilder,使其只傳回 immutable.Iterable[A] 集合,而不是預期的 Capped2[A] 集合。因此,我們覆寫 fromSpecific 和 newSpecificBuilder 運算,使其傳回 Capped2[A] 集合。另一個傳回過於一般類型的繼承運算為 empty。我們覆寫它,使其也傳回 Capped2[A] 集合。所有這些覆寫都只轉發到 iterableFactory 成員所引用的集合工廠,其值為 Capped2Factory 類別的執行個體。
Capped2Factory 類別提供方便的工廠方法來建立集合。最終,這些方法會委派給 empty 函式,它會建立一個空的 Capped2 執行個體,以及 newBuilder,它使用 appended 函式來擴充 Capped2 集合。
透過 Capped2 類別 的精緻實作,轉換函式現在能如預期般運作,而 Capped2Factory 類別提供從其他集合的無縫轉換
scala> object Capped extends Capped2Factory(capacity = 4)
defined object Capped
scala> Capped(1, 2, 3)
val res0: Capped2[Int] = Capped2(1, 2, 3)
scala> res0.take(2)
val res1: Capped2[Int] = Capped2(1, 2)
scala> res0.filter(x => x % 2 == 1)
val res2: Capped2[Int] = Capped2(1, 3)
scala> res0.map(x => x * x)
val res3: Capped2[Int] = Capped2(1, 4, 9)
scala> List(1, 2, 3, 4, 5).to(Capped)
val res4: Capped2[Int] = Capped2(2, 3, 4, 5)
此實作現在行為正確,但我們仍可以改善幾件事
- 由於我們的集合是嚴格的,我們可以利用轉換函式的嚴格實作提供的更佳效能,
- 由於我們的
fromSpecific、newSpecificBuilder和empty函式只轉發到iterableFactory成員,我們可以使用提供此類實作的IterableFactoryDefaults特質。
Capped 類別的最終版本
import scala.collection._
final class Capped[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A]
with IterableOps[A, Capped, Capped[A]]
with IterableFactoryDefaults[A, Capped]
with StrictOptimizedIterableOps[A, Capped, Capped[A]] { self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped[B] = {
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if (length == capacity) {
newElems(offset) = elem
((offset + 1) % capacity, length)
} else {
newElems(length) = elem
(offset, length + 1)
}
new Capped[B](capacity, newLength, newOffset, newElems)
}
@`inline` def :+ [B >: A](elem: B): Capped[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = view.iterator
override def view: IndexedSeqView[A] = new IndexedSeqView[A] {
def length: Int = self.length
def apply(i: Int): A = self(i)
}
override def knownSize: Int = length
override def className = "Capped"
override val iterableFactory: IterableFactory[Capped] = new CappedFactory(capacity)
}
class CappedFactory(capacity: Int) extends IterableFactory[Capped] {
def from[A](source: IterableOnce[A]): Capped[A] =
source match {
case capped: Capped[A] if capped.capacity == capacity => capped
case _ => (newBuilder[A] ++= source).result()
}
def empty[A]: Capped[A] = new Capped[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped[A]] =
new mutable.ImmutableBuilder[A, Capped[A]](empty) {
def addOne(elem: A): this.type = { elems = elems :+ elem; this }
}
}
import scala.collection.*
final class Capped[A] private (val capacity: Int, val length: Int, offset: Int, elems: Array[Any])
extends immutable.Iterable[A],
IterableOps[A, Capped, Capped[A]],
IterableFactoryDefaults[A, Capped],
StrictOptimizedIterableOps[A, Capped, Capped[A]]:
self =>
def this(capacity: Int) =
this(capacity, length = 0, offset = 0, elems = Array.ofDim(capacity))
def appended[B >: A](elem: B): Capped[B] =
val newElems = Array.ofDim[Any](capacity)
Array.copy(elems, 0, newElems, 0, capacity)
val (newOffset, newLength) =
if length == capacity then
newElems(offset) = elem
((offset + 1) % capacity, length)
else
newElems(length) = elem
(offset, length + 1)
Capped[B](capacity, newLength, newOffset, newElems)
end appended
inline def :+ [B >: A](elem: B): Capped[B] = appended(elem)
def apply(i: Int): A = elems((i + offset) % capacity).asInstanceOf[A]
def iterator: Iterator[A] = view.iterator
override def view: IndexedSeqView[A] = new IndexedSeqView[A]:
def length: Int = self.length
def apply(i: Int): A = self(i)
override def knownSize: Int = length
override def className = "Capped"
override val iterableFactory: IterableFactory[Capped] = new CappedFactory(capacity)
end Capped
class CappedFactory(capacity: Int) extends IterableFactory[Capped]:
def from[A](source: IterableOnce[A]): Capped[A] =
source match
case capped: Capped[?] if capped.capacity == capacity => capped.asInstanceOf[Capped[A]]
case _ => (newBuilder[A] ++= source).result()
def empty[A]: Capped[A] = Capped[A](capacity)
def newBuilder[A]: mutable.Builder[A, Capped[A]] =
new mutable.ImmutableBuilder[A, Capped[A]](empty):
def addOne(elem: A): this.type = { elems = elems :+ elem; this }
end CappedFactory
這就是了。最後的 Capped 類別
- 延伸
StrictOptimizedIterableOps特質,它會覆寫所有轉換函式以利用嚴格的建構函式, - 延伸
IterableFactoryDefaults特質,它會覆寫fromSpecific、newSpecificBuilder和empty函式以轉發到iterableFactory, - 為了效能,覆寫了一些操作:
view現在使用索引存取,而iterator則委派給檢視。同時也覆寫knownSize操作,因為大小始終已知。
其實作需要一點點的協定。基本上,除了繼承自集合類型之外,你還必須繼承 Ops 範本特徵,覆寫 iterableFactory 成員以傳回更具體的工廠,最後實作抽象方法(例如我們案例中的 iterator),如果有任何的話。
RNA 序列
從第二個範例開始,假設你想要為 RNA 鏈建立新的不可變序列類型。這些是 A(腺嘌呤)、U(尿嘧啶)、G(鳥嘌呤)和 C(胞嘧啶)的序列。定義這些鹼基的方式如下所示,列在 RNA 鹼基中
abstract class Base
case object A extends Base
case object U extends Base
case object G extends Base
case object C extends Base
object Base {
val fromInt: Int => Base = Array(A, U, G, C)
val toInt: Base => Int = Map(A -> 0, U -> 1, G -> 2, C -> 3)
}
每個鹼基都定義為繼承自共用抽象類別 Base 的案例物件。Base 類別有一個伴隨物件,定義了兩個在鹼基和整數 0 到 3 之間進行對應的函式。
你可以在上述範例中看到使用集合實作這些函式的兩種不同方式。toInt 函式實作為從 Base 值到整數的 Map。反向函式 fromInt 則實作為陣列。這利用了地圖和陣列都是函式的這個事實,因為它們繼承自 Function1 特徵。
enum Base:
case A, U, G, C
object Base:
val fromInt: Int => Base = values
val toInt: Base => Int = _.ordinal
每個鹼基都定義為 Base 列舉的案例。Base 有個伴隨物件,定義了兩個在鹼基和整數 0 到 3 之間進行對應的函式。
函式 toInt 是透過委派給 Base 上定義的 ordinal 方法來實作的,而這個方法會自動定義,因為 Base 是列舉。每個列舉案例都會有一個獨特的 ordinal 值。反向函式 fromInt 則實作為一個陣列。這會使用到陣列就是函式的這個事實,因為它們繼承自 Function1 特質。
接下來的任務是定義一個 RNA 序列的類別。在概念上,RNA 序列只是一個 Seq[Base]。然而,RNA 序列可能會變得相當長,因此在精簡的表示法上投資一些心力是有意義的。由於只有四個鹼基,所以一個鹼基可以用兩個位元來識別,因此你可以將十六個鹼基儲存在一個整數中,作為兩個位元的數值。因此,這個想法是建構一個 Seq[Base] 的特殊子類別,它使用這個封裝的表示法。
RNA 序列類別的第一個版本
import collection.mutable
import collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA1 private (
val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base]
with IndexedSeqOps[Base, IndexedSeq, RNA1] {
import RNA1._
def apply(idx: Int): Base = {
if (idx < 0 || length <= idx)
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
}
override protected def fromSpecific(coll: IterableOnce[Base]): RNA1 =
fromSeq(coll.iterator.toSeq)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA1] =
iterableFactory.newBuilder[Base].mapResult(fromSeq)
override def empty: RNA1 = fromSeq(Seq.empty)
override def className = "RNA1"
}
object RNA1 {
// Number of bits necessary to represent group
private val S = 2
// Number of groups that fit in an Int
private val N = 32 / S
// Bitmask to isolate a group
private val M = (1 << S) - 1
def fromSeq(buf: collection.Seq[Base]): RNA1 = {
val groups = new Array[Int]((buf.length + N - 1) / N)
for (i <- 0 until buf.length)
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA1(groups, buf.length)
}
def apply(bases: Base*) = fromSeq(bases)
}
import collection.mutable
import collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA1 private
( val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base],
IndexedSeqOps[Base, IndexedSeq, RNA1]:
import RNA1.*
def apply(idx: Int): Base =
if idx < 0 || length <= idx then
throw IndexOutOfBoundsException()
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
override protected def fromSpecific(coll: IterableOnce[Base]): RNA1 =
fromSeq(coll.iterator.toSeq)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA1] =
iterableFactory.newBuilder[Base].mapResult(fromSeq)
override def empty: RNA1 = fromSeq(Seq.empty)
override def className = "RNA1"
end RNA1
object RNA1:
// Number of bits necessary to represent group
private val S = 2
// Number of groups that fit in an Int
private val N = 32 / S
// Bitmask to isolate a group
private val M = (1 << S) - 1
def fromSeq(buf: collection.Seq[Base]): RNA1 =
val groups = new Array[Int]((buf.length + N - 1) / N)
for i <- 0 until buf.length do
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA1(groups, buf.length)
def apply(bases: Base*) = fromSeq(bases)
end RNA1
上面 RNA 序列類別清單 呈現了這個類別的第一個版本。類別 RNA1 有建構函式,它將一個 Int 陣列作為第一個引數。這個陣列包含封裝的 RNA 資料,每個元素有十六個鹼基,最後一個陣列元素除外,它可能是部分填滿的。第二個引數 length 指定陣列(和序列)上的鹼基總數。類別 RNA1 延伸 IndexedSeq[Base] 和 IndexedSeqOps[Base, IndexedSeq, RNA1]。這些特質定義了以下的抽象方法
length,透過定義同名的參數欄位來自動實作,apply(索引方法),實作方式是先從groups陣列中萃取整數值,再使用右位移 (>>) 和遮罩 (&) 從該整數中萃取正確的兩位元數字。私有常數S、N和M來自RNA1伴隨物件。S指定每個封包的大小(即兩個);N指定每個整數的兩位元封包數;M是位元遮罩,用來隔離一個字詞中最低的S位元。
我們也覆寫了轉換作業(例如 filter 和 take)使用的下列成員
fromSpecific,實作方式是使用RNA1伴隨物件的fromSeq方法newSpecificBuilder,實作方式是使用預設的IndexedSeq建構函數,並將其結果轉換成具有mapResult方法的RNA1。
Note that the constructor of class RNA1 is private. This means that
clients cannot create RNA1 sequences by calling new, which makes
sense, because it hides the representation of RNA1 sequences in terms
of packed arrays from the user. If clients cannot see what the
representation details of RNA sequences are, it becomes possible to
change these representation details at any point in the future without
affecting client code. In other words, this design achieves a good
decoupling of the interface of RNA sequences and its
implementation. However, if constructing an RNA sequence with new is
impossible, there must be some other way to create new RNA sequences,
else the whole class would be rather useless. In fact there are two
alternatives for RNA sequence creation, both provided by the RNA1
companion object. The first way is method fromSeq, which converts a
given sequence of bases (i.e., a value of type Seq[Base]) into an
instance of class RNA1. The fromSeq method does this by packing all
the bases contained in its argument sequence into an array, then
calling RNA1’s private constructor with that array and the length of
the original sequence as arguments. This makes use of the fact that a
private constructor of a class is visible in the class’s companion
object.
建立 RNA1 值的第二種方式是由 RNA1 物件中的 apply 方法提供的。它會接收可變數量的 Base 參數,並簡單地將它們作為一個序列轉發到 fromSeq。以下是這兩種建立方案的實際操作
scala> val xs = List(A, G, U, A)
val xs: List[Base] = List(A, G, U, A)
scala> RNA1.fromSeq(xs)
val res1: RNA1 = RNA1(A, G, U, A)
scala> val rna1 = RNA1(A, U, G, G, C)
val rna1: RNA1 = RNA1(A, U, G, G, C)
另外請注意我們繼承自 IndexedSeqOps 特徵的類型參數:Base、IndexedSeq 和 RNA1。第一個代表元素的類型,第二個代表轉換操作使用的類型建構函式,該操作會傳回具有不同元素類型的集合,第三個代表轉換操作使用的類型,該操作會傳回具有相同元素類型的集合。在我們的案例中,值得注意的是第二個是 IndexedSeq,而第三個是 RNA1。這表示像 map 或 flatMap 之類的操作會傳回 IndexedSeq,而像 take 或 filter 之類的操作會傳回 RNA1。
以下是顯示 take 和 filter 用法的範例
scala> val rna1_2 = rna1.take(3)
val rna1_2: RNA1 = RNA1(A, U, G)
scala> val rna1_3 = rna1.filter(_ != U)
val rna1_3: RNA1 = RNA1(A, G, G, C)
處理 map 和相關函式
不過,傳回具有不同元素類型的集合的轉換操作總是會傳回 IndexedSeq。
這些方法應該如何調整成 RNA 序列?理想的行為會是在將鹼基對應到鹼基或使用 ++ 附加兩個 RNA 序列時,取回 RNA 序列
scala> val rna = RNA(A, U, G, G, C)
val rna: RNA = RNA(A, U, G, G, C)
scala> rna.map { case A => U case b => b }
val res7: RNA = RNA(U, U, G, G, C)
scala> rna ++ rna
val res8: RNA = RNA(A, U, G, G, C, A, U, G, G, C)
另一方面,將鹼基對應到 RNA 序列中的其他類型無法產生另一個 RNA 序列,因為新元素的類型錯誤。它必須產生序列。同樣地,將非 Base 類型的元素附加到 RNA 序列可以產生一般序列,但無法產生另一個 RNA 序列。
scala> rna.map(Base.toInt)
val res2: IndexedSeq[Int] = Vector(0, 1, 2, 2, 3)
scala> rna ++ List("missing", "data")
val res3: IndexedSeq[java.lang.Object] =
Vector(A, U, G, G, C, missing, data)
這是您在理想情況下會預期的內容。但這並非 RNA1 類別 所提供的。事實上,所有範例都會傳回 Vector 的執行個體,而不仅仅是最後兩個。如果您使用此類別的執行個體執行以上前三個指令,您會取得
scala> val rna1 = RNA1(A, U, G, G, C)
val rna1: RNA1 = RNA1(A, U, G, G, C)
scala> rna1.map { case A => U case b => b }
val res0: IndexedSeq[Base] = Vector(U, U, G, G, C)
scala> rna1 ++ rna1
val res1: IndexedSeq[Base] = Vector(A, U, G, G, C, A, U, G, G, C)
因此,map 和 ++ 的結果永遠不會是 RNA 序列,即使已產生集合的元素類型為 Base。若要了解如何做得更好,不妨仔細查看 map 方法(或具有類似簽章的 ++)的簽章。 map 方法最初定義在 scala.collection.IterableOps 類別中,簽章如下
def map[B](f: A => B): CC[B]
其中 A 是集合元素的類型,而 CC 是傳遞給 IterableOps 特徵的第二個參數的類型建構函數。
在我們的 RNA1 實作中,此 CC 類型建構函數為 IndexedSeq,這就是我們總是會取得 Vector 作為結果的原因。
RNA 序列類別的第二個版本
import scala.collection.{ View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA2 private (val groups: Array[Int], val length: Int)
extends IndexedSeq[Base] with IndexedSeqOps[Base, IndexedSeq, RNA2] {
import RNA2._
def apply(idx: Int): Base = // as before
override protected def fromSpecific(coll: IterableOnce[Base]): RNA2 = // as before
override protected def newSpecificBuilder: mutable.Builder[Base, RNA2] = // as before
override def empty: RNA2 = // as before
override def className = "RNA2"
// Overloading of `appended`, `prepended`, `appendedAll`,
// `prependedAll`, `map`, `flatMap` and `concat` to return an `RNA2`
// when possible
def concat(suffix: IterableOnce[Base]): RNA2 =
fromSpecific(iterator ++ suffix.iterator)
// symbolic alias for `concat`
@inline final def ++ (suffix: IterableOnce[Base]): RNA2 = concat(suffix)
def appended(base: Base): RNA2 =
fromSpecific(new View.Appended(this, base))
def appendedAll(suffix: IterableOnce[Base]): RNA2 =
concat(suffix)
def prepended(base: Base): RNA2 =
fromSpecific(new View.Prepended(base, this))
def prependedAll(prefix: IterableOnce[Base]): RNA2 =
fromSpecific(prefix.iterator ++ iterator)
def map(f: Base => Base): RNA2 =
fromSpecific(new View.Map(this, f))
def flatMap(f: Base => IterableOnce[Base]): RNA2 =
fromSpecific(new View.FlatMap(this, f))
}
import scala.collection.{ View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA2 private (val groups: Array[Int], val length: Int)
extends IndexedSeq[Base], IndexedSeqOps[Base, IndexedSeq, RNA2]:
import RNA2.*
def apply(idx: Int): Base = // as before
override protected def fromSpecific(coll: IterableOnce[Base]): RNA2 = // as before
override protected def newSpecificBuilder: mutable.Builder[Base, RNA2] = // as before
override def empty: RNA2 = // as before
override def className = "RNA2"
// Overloading of `appended`, `prepended`, `appendedAll`,
// `prependedAll`, `map`, `flatMap` and `concat` to return an `RNA2`
// when possible
def concat(suffix: IterableOnce[Base]): RNA2 =
fromSpecific(iterator ++ suffix.iterator)
// symbolic alias for `concat`
inline final def ++ (suffix: IterableOnce[Base]): RNA2 = concat(suffix)
def appended(base: Base): RNA2 =
fromSpecific(View.Appended(this, base))
def appendedAll(suffix: IterableOnce[Base]): RNA2 =
concat(suffix)
def prepended(base: Base): RNA2 =
fromSpecific(View.Prepended(base, this))
def prependedAll(prefix: IterableOnce[Base]): RNA2 =
fromSpecific(prefix.iterator ++ iterator)
def map(f: Base => Base): RNA2 =
fromSpecific(View.Map(this, f))
def flatMap(f: Base => IterableOnce[Base]): RNA2 =
fromSpecific(View.FlatMap(this, f))
end RNA2
若要解決此缺點,您需要為 B 已知為 Base 的情況覆寫傳回 IndexedSeq[B] 的方法,以傳回 RNA2。
與 類別 RNA1 相較,我們為方法 concat、appended、appendedAll、prepended、prependedAll、map 和 flatMap 加入覆寫。
此實作現在行為正確,但我們仍可改善一些事情。由於我們的集合是嚴格的,我們可以在轉換作業中利用嚴格建構函式提供的更佳效能。此外,如果我們嘗試將 Iterable[Base] 轉換為 RNA2,它會失敗
scala> val bases: Iterable[Base] = List(A, U, C, C)
val bases: Iterable[Base] = List(A, U, C, C)
scala> bases.to(RNA2)
^
error: type mismatch;
found : RNA2.type
required: scala.collection.Factory[Base,?]
scala> val bases: Iterable[Base] = List(A, U, C, C)
val bases: Iterable[Base] = List(A, U, C, C)
scala> bases.to(RNA2)
-- [E007] Type Mismatch Error: -------------------------------------------------
1 |bases.to(RNA2)
| ^^^^
| Found: RNA2.type
| Required: scala.collection.Factory[Base, Any]
|
| longer explanation available when compiling with `-explain`
RNA 鏈類別的最終版本
import scala.collection.{ AbstractIterator, SpecificIterableFactory, StrictOptimizedSeqOps, View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA private (
val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base]
with IndexedSeqOps[Base, IndexedSeq, RNA]
with StrictOptimizedSeqOps[Base, IndexedSeq, RNA] { rna =>
import RNA._
// Mandatory implementation of `apply` in `IndexedSeqOps`
def apply(idx: Int): Base = {
if (idx < 0 || length <= idx)
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
}
// Mandatory overrides of `fromSpecific`, `newSpecificBuilder`,
// and `empty`, from `IterableOps`
override protected def fromSpecific(coll: IterableOnce[Base]): RNA =
RNA.fromSpecific(coll)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA] =
RNA.newBuilder
override def empty: RNA = RNA.empty
// Overloading of `appended`, `prepended`, `appendedAll`, `prependedAll`,
// `map`, `flatMap` and `concat` to return an `RNA` when possible
def concat(suffix: IterableOnce[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
@inline final def ++ (suffix: IterableOnce[Base]): RNA = concat(suffix)
def appended(base: Base): RNA =
(newSpecificBuilder ++= this += base).result()
def appendedAll(suffix: Iterable[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
def prepended(base: Base): RNA =
(newSpecificBuilder += base ++= this).result()
def prependedAll(prefix: Iterable[Base]): RNA =
(newSpecificBuilder ++= prefix ++= this).result()
def map(f: Base => Base): RNA =
strictOptimizedMap(newSpecificBuilder, f)
def flatMap(f: Base => IterableOnce[Base]): RNA =
strictOptimizedFlatMap(newSpecificBuilder, f)
// Optional re-implementation of iterator,
// to make it more efficient.
override def iterator: Iterator[Base] = new AbstractIterator[Base] {
private var i = 0
private var b = 0
def hasNext: Boolean = i < rna.length
def next(): Base = {
b = if (i % N == 0) groups(i / N) else b >>> S
i += 1
Base.fromInt(b & M)
}
}
override def className = "RNA"
}
object RNA extends SpecificIterableFactory[Base, RNA] {
private val S = 2 // number of bits in group
private val M = (1 << S) - 1 // bitmask to isolate a group
private val N = 32 / S // number of groups in an Int
def fromSeq(buf: collection.Seq[Base]): RNA = {
val groups = new Array[Int]((buf.length + N - 1) / N)
for (i <- 0 until buf.length)
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA(groups, buf.length)
}
// Mandatory factory methods: `empty`, `newBuilder`
// and `fromSpecific`
def empty: RNA = fromSeq(Seq.empty)
def newBuilder: mutable.Builder[Base, RNA] =
mutable.ArrayBuffer.newBuilder[Base].mapResult(fromSeq)
def fromSpecific(it: IterableOnce[Base]): RNA = it match {
case seq: collection.Seq[Base] => fromSeq(seq)
case _ => fromSeq(mutable.ArrayBuffer.from(it))
}
}
import scala.collection.{ AbstractIterator, SpecificIterableFactory, StrictOptimizedSeqOps, View, mutable }
import scala.collection.immutable.{ IndexedSeq, IndexedSeqOps }
final class RNA private
( val groups: Array[Int],
val length: Int
) extends IndexedSeq[Base],
IndexedSeqOps[Base, IndexedSeq, RNA],
StrictOptimizedSeqOps[Base, IndexedSeq, RNA]:
rna =>
import RNA.*
// Mandatory implementation of `apply` in `IndexedSeqOps`
def apply(idx: Int): Base =
if idx < 0 || length <= idx then
throw new IndexOutOfBoundsException
Base.fromInt(groups(idx / N) >> (idx % N * S) & M)
// Mandatory overrides of `fromSpecific`, `newSpecificBuilder`,
// and `empty`, from `IterableOps`
override protected def fromSpecific(coll: IterableOnce[Base]): RNA =
RNA.fromSpecific(coll)
override protected def newSpecificBuilder: mutable.Builder[Base, RNA] =
RNA.newBuilder
override def empty: RNA = RNA.empty
// Overloading of `appended`, `prepended`, `appendedAll`, `prependedAll`,
// `map`, `flatMap` and `concat` to return an `RNA` when possible
def concat(suffix: IterableOnce[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
inline final def ++ (suffix: IterableOnce[Base]): RNA = concat(suffix)
def appended(base: Base): RNA =
(newSpecificBuilder ++= this += base).result()
def appendedAll(suffix: Iterable[Base]): RNA =
strictOptimizedConcat(suffix, newSpecificBuilder)
def prepended(base: Base): RNA =
(newSpecificBuilder += base ++= this).result()
def prependedAll(prefix: Iterable[Base]): RNA =
(newSpecificBuilder ++= prefix ++= this).result()
def map(f: Base => Base): RNA =
strictOptimizedMap(newSpecificBuilder, f)
def flatMap(f: Base => IterableOnce[Base]): RNA =
strictOptimizedFlatMap(newSpecificBuilder, f)
// Optional re-implementation of iterator,
// to make it more efficient.
override def iterator: Iterator[Base] = new AbstractIterator[Base]:
private var i = 0
private var b = 0
def hasNext: Boolean = i < rna.length
def next(): Base =
b = if i % N == 0 then groups(i / N) else b >>> S
i += 1
Base.fromInt(b & M)
override def className = "RNA"
end RNA
object RNA extends SpecificIterableFactory[Base, RNA]:
private val S = 2 // number of bits in group
private val M = (1 << S) - 1 // bitmask to isolate a group
private val N = 32 / S // number of groups in an Int
def fromSeq(buf: collection.Seq[Base]): RNA =
val groups = new Array[Int]((buf.length + N - 1) / N)
for i <- 0 until buf.length do
groups(i / N) |= Base.toInt(buf(i)) << (i % N * S)
new RNA(groups, buf.length)
// Mandatory factory methods: `empty`, `newBuilder`
// and `fromSpecific`
def empty: RNA = fromSeq(Seq.empty)
def newBuilder: mutable.Builder[Base, RNA] =
mutable.ArrayBuffer.newBuilder[Base].mapResult(fromSeq)
def fromSpecific(it: IterableOnce[Base]): RNA = it match
case seq: collection.Seq[Base] => fromSeq(seq)
case _ => fromSeq(mutable.ArrayBuffer.from(it))
end RNA
最終的 RNA 類別
- 延伸
StrictOptimizedSeqOps特徵,這會覆寫所有轉換作業以利用嚴格建構函式, - 使用
StrictOptimizedSeqOps特徵提供的公用程式作業,例如strictOptimizedConcat來實作回傳RNA集合的轉換作業的超載, - 有一個延伸
SpecificIterableFactory[Base, RNA]的伴隨物件,這使得它可以用作to呼叫的參數 (將任何基礎集合轉換為RNA,例如List(U, A, G, C).to(RNA)), - 將
newSpecificBuilder和fromSpecific實作移到伴隨物件。
到目前為止的討論都集中在定義新序列所需的最小定義量,方法是遵守特定類型。但在實務上,您可能也想為序列新增新功能,或覆寫現有方法以提升效率。一個例子是類別 RNA 中覆寫的 iterator 方法。iterator 本身是一個重要的方法,因為它實作了集合的迴圈。此外,許多其他集合方法都實作於 iterator 中。因此,花點功夫最佳化方法的實作是有意義的。 IndexedSeq 中 iterator 的標準實作只會使用 apply 選取集合中每個第 i 個元素,其中 i 的範圍從 0 到集合的長度減一。因此,這個標準實作會選取一個陣列元素,並為 RNA 鏈中的每個元素解壓縮一次鹼基。類別 RNA 中覆寫的 iterator 比這更聰明。對於每個選取的陣列元素,它會立即將指定的函式套用至其中包含的所有鹼基。因此,陣列選取和位元解壓縮的工作量大幅減少。
前綴對應
作為第三個範例,您將會學習如何將一種新的可變動映射整合到集合架構中。這個想法是透過「Patricia 樹」來實作一個以 String 作為鍵類型的可變動映射。Patricia 這個術語實際上是「用於擷取以字母數字編碼的資訊的實用演算法」的縮寫,而 trie 來自於 retrieval(trie 也稱為基數樹或前綴樹)。這個想法是將一個集合或映射儲存在一個樹狀結構中,其中搜尋鍵中的後續字元會唯一地決定通過樹狀結構的一條路徑。例如,儲存字串「abc」、「abd」、「al」、「all」和「xy」的 Patricia 樹狀結構會像這樣
一個範例的 Patricia 樹狀結構: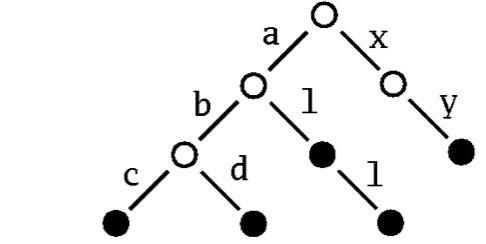
若要在此樹狀結構中找出對應於字串「abc」的節點,只要依序通過標籤為「a」的子樹、「b」的子樹,最後到達標籤為「c」的子樹即可。如果 Patricia 樹狀結構用作映射,則與鍵關聯的值會儲存在可透過鍵存取的節點中。如果它是一個集合,您只要儲存一個標記,表示該節點存在於集合中即可。
Patricia 樹狀結構支援非常有效率的查詢和更新。另一個不錯的功能是,它們支援透過提供前綴來選取子集合。例如,在上面的 Patricia 樹狀結構中,您只要從樹狀結構的根節點通過「a」連結,就能取得所有以「a」開頭的鍵的子集合。
基於這些概念,我們現在將引導您逐步實作以 Patricia 樹狀結構為基礎的地圖。我們將地圖稱為 PrefixMap,這表示它提供一個方法 withPrefix,用於選取以特定字首開頭的所有金鑰的子地圖。我們將先定義一個字首地圖,其金鑰顯示在執行範例中
scala> val m = PrefixMap("abc" -> 0, "abd" -> 1, "al" -> 2,
"all" -> 3, "xy" -> 4)
val m: PrefixMap[Int] = PrefixMap((abc,0), (abd,1), (al,2), (all,3), (xy,4))
然後在 m 上呼叫 withPrefix 將會產生另一個字首地圖
scala> m.withPrefix("a")
val res14: PrefixMap[Int] = PrefixMap((bc,0), (bd,1), (l,2), (ll,3))
Patricia 樹狀結構實作
import scala.collection._
import scala.collection.mutable.{ GrowableBuilder, Builder }
class PrefixMap[A]
extends mutable.Map[String, A]
with mutable.MapOps[String, A, mutable.Map, PrefixMap[A]]
with StrictOptimizedIterableOps[(String, A), mutable.Iterable, PrefixMap[A]] {
private var suffixes: immutable.Map[Char, PrefixMap[A]] = immutable.Map.empty
private var value: Option[A] = None
def get(s: String): Option[A] =
if (s.isEmpty) value
else suffixes.get(s(0)).flatMap(_.get(s.substring(1)))
def withPrefix(s: String): PrefixMap[A] =
if (s.isEmpty) this
else {
val leading = s(0)
suffixes.get(leading) match {
case None =>
suffixes = suffixes + (leading -> empty)
case _ =>
}
suffixes(leading).withPrefix(s.substring(1))
}
def iterator: Iterator[(String, A)] =
(for (v <- value.iterator) yield ("", v)) ++
(for ((chr, m) <- suffixes.iterator;
(s, v) <- m.iterator) yield (chr +: s, v))
def addOne(kv: (String, A)): this.type = {
withPrefix(kv._1).value = Some(kv._2)
this
}
def subtractOne(s: String): this.type = {
if (s.isEmpty) { val prev = value; value = None; prev }
else suffixes.get(s(0)).flatMap(_.remove(s.substring(1)))
this
}
// Overloading of transformation methods that should return a PrefixMap
def map[B](f: ((String, A)) => (String, B)): PrefixMap[B] =
strictOptimizedMap(PrefixMap.newBuilder, f)
def flatMap[B](f: ((String, A)) => IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedFlatMap(PrefixMap.newBuilder, f)
// Override `concat` and `empty` methods to refine their return type
override def concat[B >: A](suffix: IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedConcat(suffix, PrefixMap.newBuilder)
override def empty: PrefixMap[A] = new PrefixMap
// Members declared in scala.collection.mutable.Clearable
override def clear(): Unit = suffixes = immutable.Map.empty
// Members declared in scala.collection.IterableOps
override protected def fromSpecific(coll: IterableOnce[(String, A)]): PrefixMap[A] = PrefixMap.from(coll)
override protected def newSpecificBuilder: mutable.Builder[(String, A), PrefixMap[A]] = PrefixMap.newBuilder
override def className = "PrefixMap"
}
object PrefixMap {
def empty[A] = new PrefixMap[A]
def from[A](source: IterableOnce[(String, A)]): PrefixMap[A] =
source match {
case pm: PrefixMap[A] => pm
case _ => (newBuilder ++= source).result()
}
def apply[A](kvs: (String, A)*): PrefixMap[A] = from(kvs)
def newBuilder[A]: mutable.Builder[(String, A), PrefixMap[A]] =
new mutable.GrowableBuilder[(String, A), PrefixMap[A]](empty)
import scala.language.implicitConversions
implicit def toFactory[A](self: this.type): Factory[(String, A), PrefixMap[A]] =
new Factory[(String, A), PrefixMap[A]] {
def fromSpecific(it: IterableOnce[(String, A)]): PrefixMap[A] = self.from(it)
def newBuilder: mutable.Builder[(String, A), PrefixMap[A]] = self.newBuilder
}
}
import scala.collection.*
import scala.collection.mutable.{ GrowableBuilder, Builder }
class PrefixMap[A]
extends mutable.Map[String, A],
mutable.MapOps[String, A, mutable.Map, PrefixMap[A]],
StrictOptimizedIterableOps[(String, A), mutable.Iterable, PrefixMap[A]]:
private var suffixes: immutable.Map[Char, PrefixMap[A]] = immutable.Map.empty
private var value: Option[A] = None
def get(s: String): Option[A] =
if s.isEmpty then value
else suffixes.get(s(0)).flatMap(_.get(s.substring(1)))
def withPrefix(s: String): PrefixMap[A] =
if s.isEmpty then this
else
val leading = s(0)
suffixes.get(leading) match
case None =>
suffixes = suffixes + (leading -> empty)
case _ =>
suffixes(leading).withPrefix(s.substring(1))
def iterator: Iterator[(String, A)] =
(for v <- value.iterator yield ("", v)) ++
(for (chr, m) <- suffixes.iterator
(s, v) <- m.iterator yield (chr +: s, v))
def addOne(kv: (String, A)): this.type =
withPrefix(kv._1).value = Some(kv._2)
this
def subtractOne(s: String): this.type =
if s.isEmpty then { val prev = value; value = None; prev }
else suffixes.get(s(0)).flatMap(_.remove(s.substring(1)))
this
// Overloading of transformation methods that should return a PrefixMap
def map[B](f: ((String, A)) => (String, B)): PrefixMap[B] =
strictOptimizedMap(PrefixMap.newBuilder, f)
def flatMap[B](f: ((String, A)) => IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedFlatMap(PrefixMap.newBuilder, f)
// Override `concat` and `empty` methods to refine their return type
override def concat[B >: A](suffix: IterableOnce[(String, B)]): PrefixMap[B] =
strictOptimizedConcat(suffix, PrefixMap.newBuilder)
override def empty: PrefixMap[A] = PrefixMap()
// Members declared in scala.collection.mutable.Clearable
override def clear(): Unit = suffixes = immutable.Map.empty
// Members declared in scala.collection.IterableOps
override protected def fromSpecific(coll: IterableOnce[(String, A)]): PrefixMap[A] = PrefixMap.from(coll)
override protected def newSpecificBuilder: mutable.Builder[(String, A), PrefixMap[A]] = PrefixMap.newBuilder
override def className = "PrefixMap"
end PrefixMap
object PrefixMap:
def empty[A] = new PrefixMap[A]
def from[A](source: IterableOnce[(String, A)]): PrefixMap[A] =
source match
case pm: PrefixMap[A @unchecked] => pm
case _ => (newBuilder ++= source).result()
def apply[A](kvs: (String, A)*): PrefixMap[A] = from(kvs)
def newBuilder[A]: mutable.Builder[(String, A), PrefixMap[A]] =
mutable.GrowableBuilder[(String, A), PrefixMap[A]](empty)
import scala.language.implicitConversions
implicit def toFactory[A](self: this.type): Factory[(String, A), PrefixMap[A]] =
new Factory[(String, A), PrefixMap[A]]:
def fromSpecific(it: IterableOnce[(String, A)]): PrefixMap[A] = self.from(it)
def newBuilder: mutable.Builder[(String, A), PrefixMap[A]] = self.newBuilder
end PrefixMap
前一個清單顯示 PrefixMap 的定義。地圖的金鑰類型為 String,而值為參數類型 A。它延伸 mutable.Map[String, A] 和 mutable.MapOps[String, A, mutable.Map, PrefixMap[A]]。您已在 RNA 序列範例中看過這個序列模式;當時和現在一樣,繼承實作類別(例如 MapOps)用於取得轉換的正確結果類型,例如 filter。
字首地圖節點有兩個可變動欄位:suffixes 和 value。value 欄位包含與節點關聯的選用值。它初始化為 None。suffixes 欄位包含從字元到 PrefixMap 值的地圖。它初始化為空地圖。
您可能會問,為什麼我們選擇不可變動的映射作為suffixes 的實作類型?可變動的映射不是更標準嗎?因為PrefixMap 整體而言也是可變動的。答案是,僅包含少數元素的不可變動映射在空間和執行時間上都非常有效率。例如,包含少於 5 個元素的映射會表示為單一物件。相比之下,標準的可變動映射是HashMap,即使它是空的,通常也會佔用約 80 個位元組。因此,如果小型集合很常見,最好選擇不可變動的而非可變動的。在 Patricia tries 的情況下,我們預期除了樹最頂端的節點之外,大多數節點只會包含幾個後繼。因此,將這些後繼儲存在不可變動的映射中可能會更有效率。
現在來看一下地圖必須實作的第一個方法:get。演算法如下:若要取得前綴地圖中與空字串關聯的值,只要選取儲存在樹根(目前的映射)中的選用 value 即可。否則,如果金鑰字串不為空,請嘗試選取對應於字串第一個字元的子映射。如果產生映射,請接著在該映射中檢索其第一個字元之後的其餘金鑰字串。如果選取失敗,表示金鑰未儲存在映射中,因此傳回 None。使用 opt.flatMap(x => f(x)) 可優雅地表達選用值 opt 的合併選取。當套用於選用值為 None 時,它會傳回 None。否則,opt 為 Some(x),且函數 f 會套用於封裝的值 x,產生新的選項,並由 flatmap 傳回。
可變動地圖必須實作的下一種方法為 addOne 和 subtractOne。
subtractOne 方法與 get 非常類似,不同之處在於在傳回任何關聯值之前,包含該值的欄位會設定為 None。addOne 方法會先呼叫 withPrefix 來導覽至需要更新的樹狀節點,然後將該節點的 value 欄位設定為給定的值。withPrefix 方法會導覽樹狀結構,並視需要建立子對應,如果字元的前置詞尚未包含在樹狀結構的路徑中。
The last abstract method to implement for a mutable map is
iterator. This method needs to produce an iterator that yields all
key/value pairs stored in the map. For any given prefix map this
iterator is composed of the following parts: First, if the map
contains a defined value, Some(x), in the value field at its root,
then ("", x) is the first element returned from the
iterator. Furthermore, the iterator needs to traverse the iterators of
all submaps stored in the suffixes field, but it needs to add a
character in front of every key string returned by those
iterators. More precisely, if m is the submap reached from the root
through a character chr, and (s, v) is an element returned from
m.iterator, then the root’s iterator will return (chr +: s, v)
instead. This logic is implemented quite concisely as a concatenation
of two for expressions in the implementation of the iterator method in
PrefixMap. The first for expression iterates over value.iterator. This
makes use of the fact that Option values define an iterator method
that returns either no element, if the option value is None, or
exactly one element x, if the option value is Some(x).
不過,在所有這些情況中,要建立正確類型的集合,您需要從該類型的空集合開始。這是由 empty 方法提供的,它只會傳回新的 PrefixMap。
現在我們將轉向伴隨物件 PrefixMap。事實上,定義這個伴隨物件並非絕對必要,因為類別 PrefixMap 本身就可以獨立存在。物件 PrefixMap 的主要目的是定義一些方便的工廠方法。它也定義了一個隱含轉換為 Factory,以便與其他集合有更好的互操作性。當有人寫入時,例如 List("foo" -> 3).to(PrefixMap),就會觸發這個轉換。to 操作將 Factory 作為參數,但 PrefixMap 伴隨物件並未延伸 Factory(而且它不能這樣做,因為 Factory 修復了集合元素的類型,而 PrefixMap 具有多型態的值類型)。
兩個方便的方法是 empty 和 apply。Scala 集合架構中所有其他集合都有相同的方法,因此在此定義它們也很有意義。使用這兩個方法,您可以撰寫 PrefixMap 文字,就像對任何其他集合所做的那樣
scala> PrefixMap("hello" -> 5, "hi" -> 2)
val res0: PrefixMap[Int] = PrefixMap(hello -> 5, hi -> 2)
scala> res0 += "foo" -> 3
val res1: res0.type = PrefixMap(hello -> 5, hi -> 2, foo -> 3)
摘要
總之,如果您想將新的集合類別完全整合到架構中,您需要留意以下幾點
- 決定集合應該是可變的還是不可變的。
- 為集合選擇正確的基本特質。
- 從正確的實作特質繼承,以實作大部分的集合操作。
- 覆載預設情況下不會傳回集合的所需操作,因為它們可能比預期更具體。此類操作的完整清單作為附錄提供。
您現在已經看到 Scala 的集合是如何建構的,以及如何新增新的集合類型。由於 Scala 豐富的抽象化支援,每個新的集合類型都有大量的函式,而不需要重新實作所有這些函式。
致謝
此頁面包含改編自 Odersky、Spoon 和 Venners 所著的書籍 Programming in Scala 的資料。我們感謝 Artima 慷慨同意出版此書。
附錄:為了支援「相同結果類型」原則而需要覆寫的函式
您想要新增覆寫,以專門化轉換操作,以便它們傳回更具體的結果類型。範例如下:
- 當對應函式傳回
Char時,StringOps上的map應傳回String(而非IndexedSeq), - 當對應函式傳回一對時,
Map上的map應傳回Map(而非Iterable), - 當對應的元素類型有隱含的
Ordering時,SortedSet上的map應傳回SortedSet(而非Set)。
通常,當集合修正其範本特質的某個型別參數時,就會發生這種情況。例如,在 RNA 集合型別的情況下,我們將元素型別修正為 Base,而在 PrefixMap[A] 集合型別的情況下,我們將金鑰的型別修正為 String。
下表列出可能會傳回不理想寬型別的轉換運算。您可能需要覆載這些運算,以傳回更具體的型別。
| 集合 | 運算 |
|---|---|
Iterable |
map、flatMap、collect、scanLeft、scanRight、groupMap、concat、zip、zipAll、unzip |
Seq |
prepended、appended、prependedAll、appendedAll、padTo、patch |
immutable.Seq |
updated |
SortedSet |
map、flatMap、collect、zip |
Map |
map、flatMap、collect、concat |
immutable.Map |
updated、transform |
SortedMap |
map、flatMap、collect、concat |
immutable.SortedMap |
updated |
附錄:跨建自訂集合
由於 Scala 2.13 集合的新內部 API 與先前的集合 API 非常不同,自訂集合類型的作者應使用個別的來源目錄(每個 Scala 版本)來定義它們。
使用 sbt 時,您可以透過將以下設定新增至專案來達成此目的
// Adds a `src/main/scala-2.13+` source directory for Scala 2.13 and newer
// and a `src/main/scala-2.13-` source directory for Scala version older than 2.13
unmanagedSourceDirectories in Compile += {
val sourceDir = (sourceDirectory in Compile).value
CrossVersion.partialVersion(scalaVersion.value) match {
case Some((2, n)) if n >= 13 => sourceDir / "scala-2.13+"
case _ => sourceDir / "scala-2.13-"
}
}
然後,您可以在 src/main/scala-2.13+ 來源目錄中定義集合的 Scala 2.13 相容實作,並在 src/main/scala-2.13- 來源目錄中定義先前 Scala 版本的實作。
您可以在 scalacheck 和 scalaz 中看到此方法如何付諸實行。