與正常的順序集合函式庫類似,Scala 的平行集合函式庫包含大量集合運算,這些運算均一致存在於許多不同的平行集合實作中。而且與順序集合函式庫類似,Scala 的平行集合函式庫試圖透過同樣實作大部分運算來防止程式碼重複,這些運算以平行集合「範本」表示,只需定義一次,即可由許多不同的平行集合實作彈性繼承。
這種方法的好處大大簡化了維護和可擴充性。在維護方面,由於所有平行集合都繼承了平行集合運算的單一實作,因此維護變得更容易且更強固;錯誤修正會沿著類別階層向下傳播,而非需要複製實作。基於相同原因,整個函式庫變得更容易擴充,新的集合類別只需繼承大部分運算即可。
核心抽象
前述的「範本」特質實作大部分平行運算,其方式是根據兩個核心抽象:Splitter 和 Combiner。
Splitter
顧名思義,Splitter 的工作是將平行集合分割成非平凡的元素分割區。基本概念是將集合分割成較小的部分,直到它們小到足以順序運算。
trait Splitter[T] extends Iterator[T] {
def split: Seq[Splitter[T]]
}
有趣的是,Splitter 實作為 Iterator,表示除了分割之外,架構也會使用它們來橫越平行集合(也就是說,它們繼承 Iterator 的標準方法,例如 next 和 hasNext。)這種「分割迭代器」的獨特之處在於,它的 split 方法會將 this(再次說明,Splitter,一種 Iterator)進一步分割成其他 Splitter,每個 Splitter 都會橫越整個平行集合元素的不相交子集合。類似於一般 Iterator,Splitter 在呼叫其 split 方法後會失效。
一般來說,集合會使用 Splitter 分割成大小大致相同的子集合。在需要更任意大小的分割時,特別是在平行序列中,會使用 PreciseSplitter,它繼承 Splitter,並另外實作精確分割方法 psplit。
組合器
Combiner 可以視為 Scala 順序集合函式庫中的概化 Builder。每個平行集合提供個別的 Combiner,就像每個順序集合提供 Builder 一樣。
在順序集合的情況下,元素可以新增至 Builder,並可透過呼叫 result 方法來產生集合,在平行集合的情況下,Combiner 有個名為 combine 的方法,它會接受另一個 Combiner 並產生一個新的 Combiner,其中包含兩者的元素聯集。呼叫 combine 之後,兩個 Combiner 都會失效。
trait Combiner[Elem, To] extends Builder[Elem, To] {
def combine(other: Combiner[Elem, To]): Combiner[Elem, To]
}
上述兩個型別參數 Elem 和 To 分別表示元素型別和結果集合的型別。
注意:假設有兩個 Combiner,c1 和 c2,其中 c1 eq c2 為 true(表示它們是同一個 Combiner),呼叫 c1.combine(c2) 永遠不會做任何事,只會傳回接收的 Combiner,c1。
階層結構
Scala 的平行集合在設計上深受 Scala(順序)集合函式庫的啟發,事實上,它反映了常規集合架構對應的特質,如下所示。
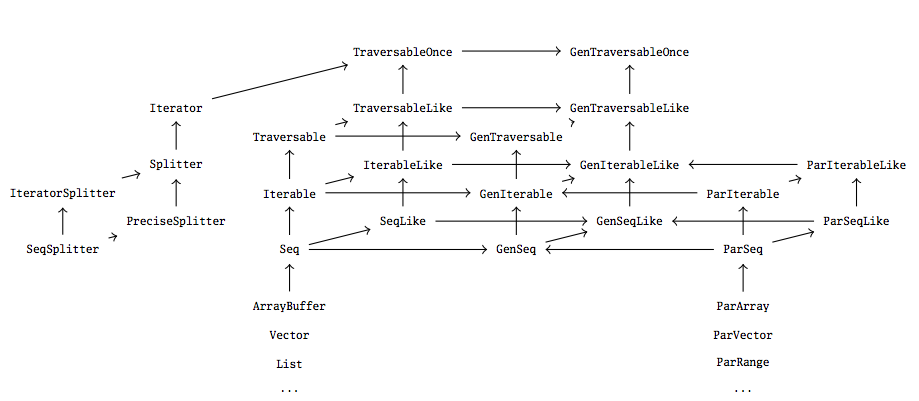
目標當然是讓平行集合與順序集合緊密整合,以允許順序集合和平行集合進行直接替換。
為了能夠參考可能是順序或並行的集合(這樣就可以透過呼叫 par 和 seq 來在並行集合和順序集合之間「切換」),必須存在這兩種集合類型的共同超類型。這是上面顯示的「一般」特質的起源,GenTraversable、GenIterable、GenSeq、GenMap 和 GenSet,它們不保證順序或一次一個地進行遍歷。對應的順序或並行特質繼承自這些特質。例如,ParSeq 和 Seq 都是一般序列 GenSeq 的子類型,但它們彼此之間沒有繼承關係。
如需有關順序和並行集合之間共用階層的更詳細說明,請參閱技術報告。 [1]